*written by PeterAlbus,Copyright © 2022 - SHOU 1951123 Hong Wu*
# 软件工程
### 附录 面向对象软件工程各个阶段及主要任务
+ 需求分析
+ 从与用户的沟通中获得需求
+ 建立需求模型——用例图
+ 用例图及用例规约
+ 补充规约
+ 编写术语表
+ 软件分析
+ 识别与确定分析类——边界类、控制类、实体类
+ 建立对象-行为模型——时序图/协作图
+ 建立对象-关系模型——参与类图与合并参与类图
+ 软件设计
+ 系统架构设计
+ 高层结构设计(架构模式,MVC等)
+ 确定设计元素、任务管理策略、分布式实现、数据存储、设计人机交互
+ 系统元素设计
+ 子系统和分包
+ 类/对象设计——详细的类图
+ 编码
+ 同时完成单元测试
+ 软件测试
+ 确认测试
+ 黑盒测试
+ 等价类分析法、边界值法、猜错法
+ 得到测试用例:{测试数据+期望结果}
+ 白盒测试
+ 逻辑覆盖测试:根据流程图
+ 路径测试:流程图=>程序图
+ 得到测试用例
+ 运行维护
### 第一章 绪论
#### 1.1 软件和软件危机
##### 1.1.1 软件的定义
软件=程序+文档
##### 1.1.3 软件危机
> ***软件危机*是指落后的软件生产方式无法满足迅速增长的计算机软件需求,从而导致软件开发与维护过程中出现一系列严重问题的现象。**
随着计算机应用的逐步扩大,软件的需求量也迅速增加,规模日益增长。开发一个数万乃至于数百万行的代码,其复杂度将会大大增加。这导致大型软件的开发费用往往超出预算,完成时间也常常脱期。庞大的软件费用和软件质量的下降对计算机应用的继续扩大构成了巨大的威胁。面对这种严峻的形势,软件界一些有识之士提出了软件危机的警告。
软件危机出现的原因有维护和生产两个方面:
+ 软件维护费用急剧上升,直接威胁计算机应用的扩大
+ 软件生产技术进步缓慢,是加剧软件危机的重要原因——许多人士意识到必须把软件生产从个人化方式改变为工程化方式
#### 1.2 软件工程学的范畴
“软件工程”一词,是1968年北大西洋公约组织(NATO)在联邦德国召开的一次会议上提出的。它反映了软件人员认识到软件危机的出现,以及为谋求解决这一危机而做的一种努力。
软件工程有着各种各样的定义。无论多少种说法,它的中心思想都是**把软件当作一种工业产品,要求“采用工程化的原理与方法对软件进行计划、开发和维护”**。

##### 1.2.3 软件工程环境
> 方法与工具相结合,再加上配套的软、硬件支持就形成环境。
创建适用的**软件工程环境(software enginerring environment, SE)**,一直是软件工程研究中的热门课题。
#### 1.3 软件工程的发展
自1968年首次提出软件工程概念以来,已经经过了40年,在这一时期中,编程泛型(programming paradigm)已经经历了3次演变,软件工程也从第一代发展到了第三代。
##### 1.3.1 3种编程范型
1. 过程式编程范型
过程式编程范型遵循“程序=数据结构+算法”的思路,把程序理解为由一组被动的数据和一组能动的过程组成。编程时,先设计数据结构,再围绕数据结构编写其算法过程。
典型:FORTRAN、Pascal、C
由于客观事物中,实体的“状态”(数据)和"运动"(方法)总是结合在一起的,但使用POPL(面向过程编码语言,procedure-oriented programming langue)编程时,数据结构和算法是独立的,导致程序模型(解空间,solution domain)会偏离客观事物本身的模型(问题空间,problem domain),程序规模越大,这种编程泛型的缺陷更加明显。
这类范型通常只用于编写规模不大(50000行以下),不会轻易更改的程序
2. 面向对象编程范型
在面向对象的程序设计中,数据及其操作被封装在一个个称为对象(object)的统一体中,对象之间则通过消息(message)相互联系,"对象+消息"的机制取代了"数据结构+算法"的思路。较好地实现了解空间和问题空间的一致性。
面向过程到面向对象程序设计(object-oriented programming, OOP)是程序设计方法的一次飞跃。
面向对象编程泛型的优势也体现在软件的维护上,能够使得大型软件的维护更加容易和快捷。
3. 基于构件技术的编程泛型
构建(component,也译为组件)可以理解为标准化的对象类,它本质上是一种通用的,可支持不同应用程序的组件。
基于构建的开发技术(component-based development, CBD)与面向对象技术实际上是一脉相承的。CBD实际上是OO开发的延申与归宿。
4. 3种编程范型的比较
常用编程粒度的大小来比较3种编程范型的差异。
+ 过程式编程范型:着眼于程序的过程和基本控制结构,粒度最小
+ 面向对象编程范型:着眼于程序中的对象,粒度比较大
+ 基于构件技术的编程范型:着眼于适合整个领域的类对象,粒度更大
##### 1.3.2 三代软件工程
+ 传统软件工程或经典软件工程
结构化分析=>结构化设计=>面向过程的编码=>软件测试
+ 面向对象软件工程
OO分析与对象抽取=>对象详细设计=>面向对象的编码与测试
+ 基于构件的软件工程
领域分析和测试计划定制=>领域设计=>建立可复用构件库=>按“构建集成模型”查找与集成构建
## 上篇 传统软件工程
### 第二章 软件生存周期与软件过程
#### 2.1 软件生存周期
一个软件从开始立项起,到废弃不用止,统称为软件的生存周期(life cycle)。
软件生存周期分为三个时期八个阶段:
+ 三个时期:软件定义、软件开发、软件维护
+ 八个阶段:问题定义、可行性研究(可行性研究报告)、需求分析(软件需求规格说明书)、概要设计、详细设计、编码和单元测试、综合测试、运行维护
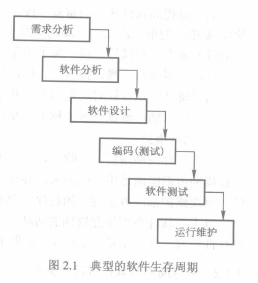
##### 2.1.1 软件生存周期的主要活动
1. 需求分析
主要弄清用户需要用计算机解决什么问题。从用户的视角对需求进行分析和定义,建立需求模型。
2. 软件分析
软件分析的任务是在系统需求模型的基础上,从开发人员的视角对软件的需求模型进行分析,建立与需求模型一致的,与实现无关的软件分析模型。它是对软件逻辑模型的描述,也是下一步进行软件设计的依据。
3. 软件设计
将软件分析模型转变为考虑具体实现技术和平台的软件设计模型,他一般又可细分为总体设计(亦称概要设计)和详细设计。总体设计确定总体结构和全局性的设计原则,详细设计则是确定软件每一个部件的数据结构和操作。
4. 编码
编码是按照选定的程序设计语言和可复用软件构件包,把设计文档翻译为源程序,与前两个阶段相比,编码的难度相对较小。
先前的阶段产生的都是软件文档,而这个阶段将产生程序。
5. 软件测试
软件测试是提高软件质量的重要手段。测试可细分为多个层次。
由于编一点测试一点,会比编完了在测试更省力。有些测试也会出现在编码阶段。
通过确认测试和系统测试,软件即可交付使用,因此确认测试有时也称为交付测试。
6. 运行维护
生存周期的最后一个阶段。任务书做好软件维护,使软件在整个生存周期内都能满足用户的需求,并延长其使用寿命。
##### 2.1.2 生存周期与软件过程的关系
对软件生存周期的研究导致了软件工程另一个概念——软件过程的诞生。
1. 从软件生存周期到过程模型
软件过程可理解为围绕软件开发所进行的一系列活动。早些时候,人们常常把软件过程称为“软件开发模型”(software development model)。著名的瀑布模型(waterfall model)是生存周期和软件过程的研究互相结合的一个早期实例。
早期的软件工程,软件开发模型包含的阶段与活动和软件生存周期划分的阶段与活动基本一致。上图显示的典型软件生存周期,也可以用来展示典型瀑布模型的阶段与活动,二者都属于线性模型,且具有等同性。它们共同特点是严格地划分阶段,各阶段的活动分步完成,前一阶段的活动没有结束,下一阶段的活动就不能进行,恰如奔流不息,拾级而下的瀑布。
2. 软件过程的演变
第一代软件过程期间瀑布模型被普遍采用。但20世纪80年代中期人们渐渐发现线性开发模型不适合大型复杂系统的开发。因为需求会频繁的更改。因此软件开发模型开始演变,陆续涌现开发过程中允许回溯和迭代的模型。
#### 2.2 传统的软件过程
##### 2.2.1 瀑布模型
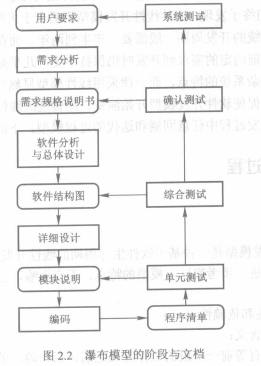
瀑布模型是基于软件生存周期的线性开发模型,有如下特点:
+ 阶段间的顺序性和依赖性
顺序性:只有等前一阶段工作完成后,后一阶段的工作才能开始
+ 推迟实现的观点
不要过早地进行编码,把开发软件的逻辑设计和物理实现清晰地区别开来。不要过早考虑实现。
+ 保证质量
每一阶段必须完成规定的文档
每一阶段都要对完成的文档进行复审
按照瀑布模型开发软件,需要分析员能够做出准确的需求分析,“在软件产品的某个版本试用之前,要用户完全、正确地对一个现代软件产品提出确切的需求,实际上是不可能的”——F. Brooks。为了解决这一问题,人们提出了快速原型模型。
##### 2.2.2 快速原型模型
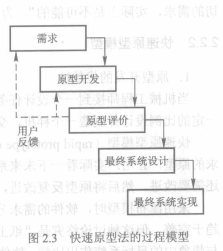
**快速原型模型**(rapid prototype model)的中心思想是,先建立一个能够反映用户主要需求的原型;让用户实际看一下未来系统的概貌,以便判断哪些功能是符合需要的,哪些方面还需要改进,之后将原型反复改进。直至符合用户要求。
原型开发时,只包括未来系统的主要功能及系统的重要接口。它不包括系统的细节,例如异常处理、对非有效输入的反应等。
而当产生实际系统时,大多原型都废弃不用。应当果断废弃原型来避免影响软件开发质量。
原型开发模型改变了“把生存周期等同于过程模型”的惯性思维。
#### 2.3 软件演化模型
随着人们逐渐熟悉非线性的开发模型,复杂软件开始使用渐增式或迭代式的开发方法。于是,一种被称为演化模型(evolutionary model)的渐进式开发模型应运而生。它遵循迭代的思想方法,有时也称为迭代化开发模型。常见的演化模型有增量模型和螺旋模型两种。
##### 2.3.1 增量模型
增量模型(incremental model)是瀑布模型的顺序特征与快速原型法的迭代特征相结合的产物。这种模型把软件看作一系列相互联系的增量(increments),开发迭代中每次完成一个增量。
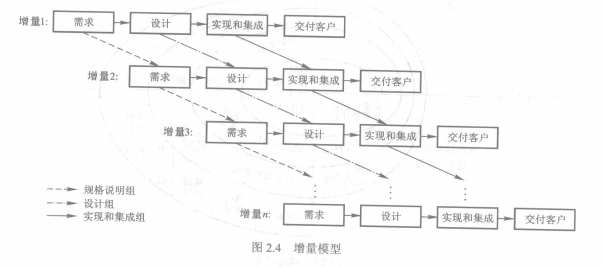
其中任意一个增量的开发流程均可按瀑布模型或快速原型法完成。
增量模型有利于控制技术风险、可为不同增量配备不同数量开发人员,使计划增加灵活性。
##### 2.3.2 螺旋模型
螺旋模型(spiral model)是目前软件开发中最常用的一种软件开发模型,是在结合瀑布模型与快速原型模型基础上演变而成的,尤其适用于大型软件的开发。
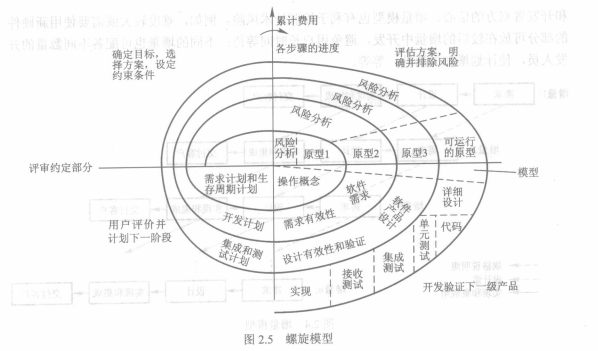
螺旋模型是一种典型的迭代模型,每迭代一次,螺旋线前进一周。
每轮螺旋都包含以下四个活动,按顺序周而复始,直至实现
1. 计划。用于选定本轮螺旋所定目标的策略,包括确定待开发系统的目标,选择方案,设定约束。
2. 风险分析,评估本轮螺旋存在的风险,然后觉得是否按原定目标执行,亦或修改/中止项目。
3. 建立原型,建立一个原型来实现本轮螺旋的目标。第一圈可能产生需求规格说明书,第二圈实现产品设计等。
4. 用户评审,让用户评价前一步结果,计划下一步工作
软件开发时存在着风险。对于高风险的大型软件,螺旋模型较为理想,螺旋模型任意一次迭代均可应用原型方法降低风险,总体上保留了瀑布模型的顺序性。
螺旋模型的特点就是在项目各阶段都考虑风险。螺旋模型开发的成败,在很大程度上依赖于风险评估的准确性。
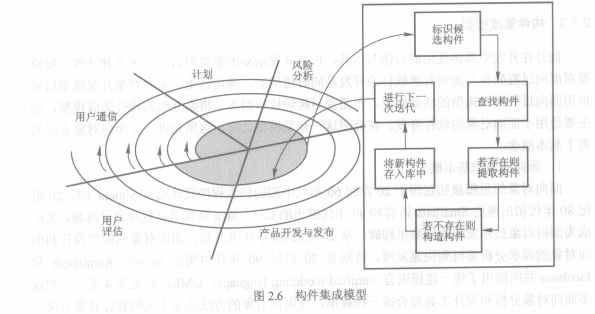
##### 2.3.3 构件集成模型
上述软件开发模型同时适用于面向过程和面向对象软件开发。构建集成模型则主要适用于面向对象软件开发。
构建集成模型利用预先封装好的构建来构造应用系统,它融合了螺旋模型的不少特征,也支持软件开发的迭代方法。
#### 2.4 形式化方法模型
形式化方法模型主要研究形式化的程序变换技术。
##### 2.4.1 转换模型
采用严格的数学方法表示软件需求规格说明书,然后进行一系列自动或半自动的程序变换。
##### 2.4.2 净室模型
力求在分析和设计阶段就消除错误,确保正确,然后在无缺陷/洁净的状态下实现软件的制作。
#### 2.5 统一过程和敏捷过程
##### 2.5.1 统一过程
统一过程描述了软件开发中各个环节应该做什么,怎么做,什么时候做以及为什么要做,描述了一组以某种顺序完成的活动。
##### 2.5.2 敏捷过程
软件项目的构建被切分成多个子项目,每个子项目的成果都经过测试,具备集成和可运行的特征。
##### 2.5.3 极限编程
交流、简单、反馈、勇气
#### 2.6 软件可行性研究
确定开发是否值得进行,分析它存在哪些风险。
### 第三章 结构化分析与设计
本章节重点介绍基于瀑布模型的结构化分析与设计
#### 3.1 概述
##### 3.1.1 结构化分析与设计的由来
结构化分析与设计由结构化程序设计扩展而来。
分为结构化设计(structured design, SD)和结构化分析(structured analysis, SA)技术。
作为一种系统化开发方法,结构化分析与设计是瀑布模型的首次实践。该模型一般分为如下阶段
需求定义与分析→总体设计→详细设计→编码→测试→使用维护
+ SA与SD的流程
系统开发从需求分析开始,首先建立系统的需求模型,接着通过SD方法提供的映射规则,把分析模型转化为初始设计模型,然后再优化为系统的最终设计模型。
+ 结构化分析(工具:DFD、PSPEC)→分析模型(分层DFD图)+ SRS
+ 结构化设计(工具:SC图)→(映射) 初始设计模型(初始SC图)
+ 初始设计模型(初始SC图)→(优化) 最终设计模型(最终SC图)
+ 基本任务
+ 结构化分析
SA阶段有两个基本任务,建立系统分析模型(analysis model)和编写软件需求规格说明书(software requirements specification, SRS),两者都是必须完成的文档。
主要思想是抽象和分解。
+ 结构化设计
软件设计=总体设计+详细设计。SD阶段把分析模型中的DFD图转换成SC图,完成了总体设计。随后的详细设计中,还需要用适当的工具对各个模块采用的算法和数据结构做适当的描述。

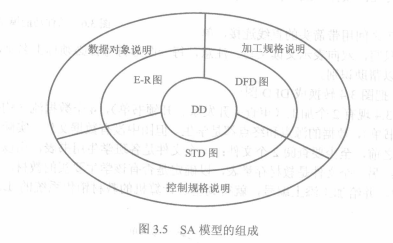
##### 3.1.2 SA模型的组成与描述
SA模型通过现实环境得出的具体模型→当前系统模型→目标系统模型→改进的目标系统模型的流程,最终得到的就是被称为DFD图的模型。
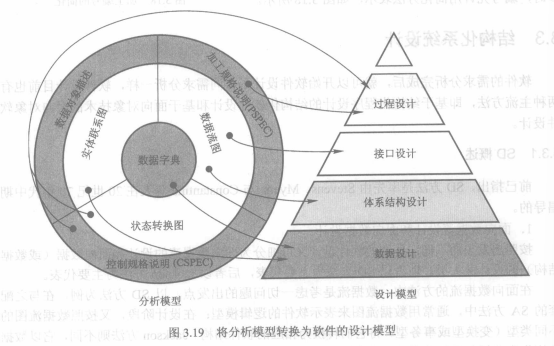
1. SA模型的组成
下图显示了SA模型的组成,**数据字典**(data dictionary, DD)处于模型的核心,它是系统涉及的各种数据对象的总和。从DD出发可以构建
+ **实体联系图**(entity-relation diagram,E-R图),描述数据对象间的关系,每个属性用**数据对象说明**描述
+ **数据流图**(data flow diagram,DFD),指明系统间数据如何流动和变换,DFD图的每个功能用**加工规格说明**(process specification, PSPEC)描述
+ **状态变换图**(status transform diagram,STD),指明系统在外部事件的作用下如何动作。软件控制方面的附加信息还可以用**控制规格说明**(control specification,CSPEC)描述
2. SA模型描述工具
+ DFD图
使用四种基本图形符号,圆框代表加工,箭头代表数据流向,方框表示数据源点和终点,双杠表示数据文件或数据库。DFD不能表示程序的控制结构。
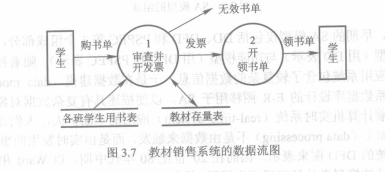
+ 数据字典
对软件中的每个数据规定一个定义条目

+ 加工规格说明
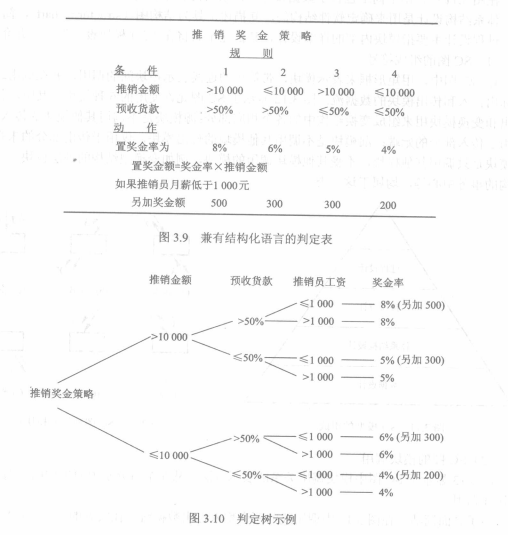
常用结构化语言、判定表或判定树作为描述工具

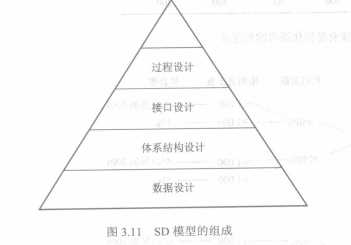
##### 3.1.3 SD模型的组成与描述
1. SD模型的组成
SD模型由SA模型映射而来,SA的数据字典可转换为数据设计,数据流图可转换为体系结构设计(SC图)和接口设计,加工规格说明可转换为模块内部的详细过程设计。
2. SD模型的描述工具
体系结构设计的描述工具为结构图(structrue chart),简称SC图
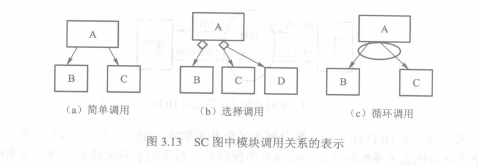
SC图由六种模块组成
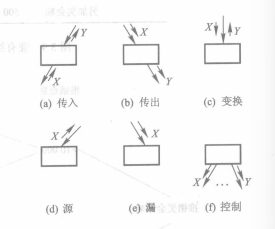
SC图的模块调用分为简单调用、选择调用和循环调用
#### 3.2 结构化系统分析
> 结构化分析就是使用DFD、DD、结构化语言、判定表和判定树等工具,来建立一种新的,称为结构化说明书的目标文档。
结构化分析的基本步骤是:自顶向下对系统进行功能分解,画出分层DFD图,由后向前定义系统的数据和加工,编制DD和PSPEC,最终写出SRS。
##### 3.2.1 画分层数据流图
大型系统DFD含有数百甚至数千个加工,不可能一次将其画完。需要从系统的基本功能模型(整个系统作为一个加工),逐层的对系统进行分解。没分解一次,系统的加工数量就会多一些,加工也更具体一点。直到加工不能再分解,这种称为基本加工。以下为逐步分解的一个例子:
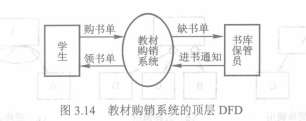
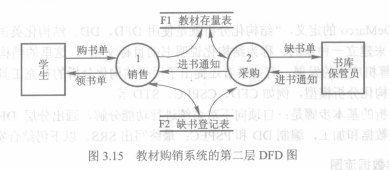
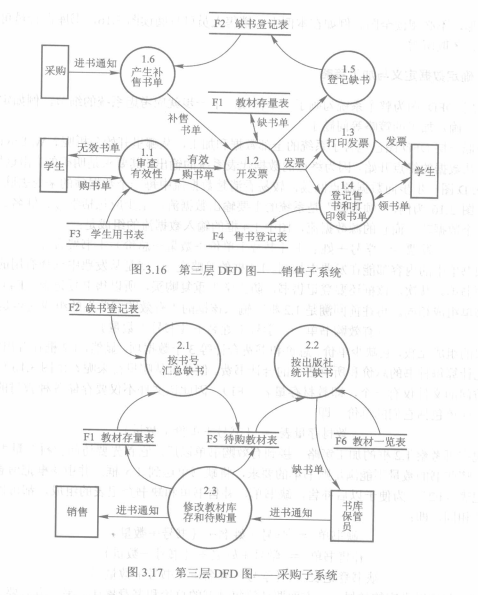
分层DFD可以避免一次引入过多细节,此外可以让不同业务人员之阅读与本身有关的图形而不必阅读总图。
##### 3.2.2 确定数据定义与加工策略
分层DFD图确定了系统的全部数据和加工。之后从DFD图的终点一步步向源点开始绘制,写出加工规格说明和数据字典,发现问题时对DFD图进行修正。最终生成一个一致统一的文档——SRS。
##### 3.2.3 需求分析的复审
需求分析完成后,应当复审其完整性、易改性和易读性,尽量多地发现文档中存在的矛盾,冗余和遗漏。
#### 3.3 结构化系统设计
在软件需求分析完成后,就可以开始软件设计了。
##### 3.3.1 SD概述
软件设计分为面向数据流设计(SD)方法和面向数据设计(Jackson方法)两大类,后者已基本过时。
##### 3.3.2 从DFD图到SC图
结构化软件设计通常从DFD图到SC图的映射开始。
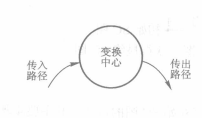
DFD数据流图分为变换型结构和事务型结构两种类型
变换型结构由传入路径,变换中心和传出路径三部分组成
事务型结构则由一条接收路径,一个事务中心与若干条动作路径组成。一个事务中心获得某一特定值,就能启动某一条动作路径的操作。
要从DFD图映射到SC图,需要先鉴别是变换型还是事务型(也可能同时存在两类结构)
然后通过变换映射将变换型DFD图转换为初始SC图
通过事务映射将事务型DFD图转换为初始SC图
##### 3.3.3 变换映射
+ 划分DFD图的边界
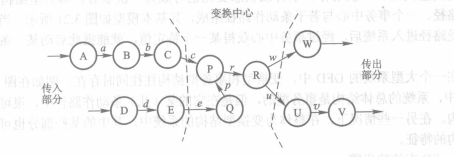
+ 建立初始SC图的框架
+ 分解SC图的各个分支
+ 将第一层分为传入模块、变换模块和传出模块,之后再对其进行分解
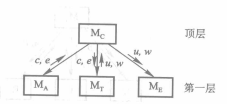
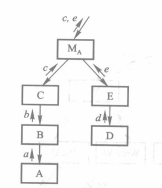
+ 最终合并在一起,形成初始SC图
##### 3.3.4 事务映射
+ DFD图上确定事务中心,接收部分和发送部分(包括全部动作路径)
+ 画出SC图框架,把三个部分映射为事务控制模块,接收模块和动作发送模块
+ 分解细化接收分支和发送分支,完成初始SC图。
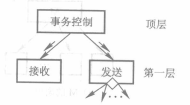
##### 3.3.5 优化初始SC图的指导规则
+ 对模块划分
一个模块的总行数应控制在10~100行
+ 高扇入/低扇出的原则
扇入高则上级模块多,能够增加模块利用率,扇出低表示下级模块少,可以减少模块调用和控制的复杂度。可以用增加中间层的方式减小扇出,煎饼形一般是不可取的。
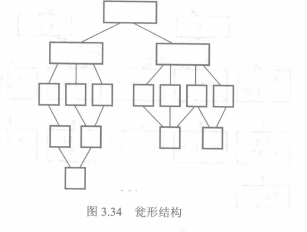
瓮型结构是最理想的结构。但这种结构往往比较难追求,大量中间模块都复用了下级模块,这是非常难做到的。
#### 3.4 模块设计
将DFD图转换为最终SC图,仅仅完成了软件设计的第一步。之后进行模块设计,对系统中的每个模块给出足够详细的逻辑描述。所以也称为详细设计。
##### 3.4.1 目的与任务
+ 为每个模块确定采用的算法
+ 确定每一模块使用的数据结构
+ 确定模块接口的细节
##### 3.4.2 模块设计的原则与方法
1. 清晰第一的程序风格
程序应当注重可读性,遵循“清晰第一、效率第二”
2. 结构化控制结构
设计中只使用单输入、单出口的3种基本控制结构
##### 3.4.3 常用的表达工具
+ 流程图和N-S图:
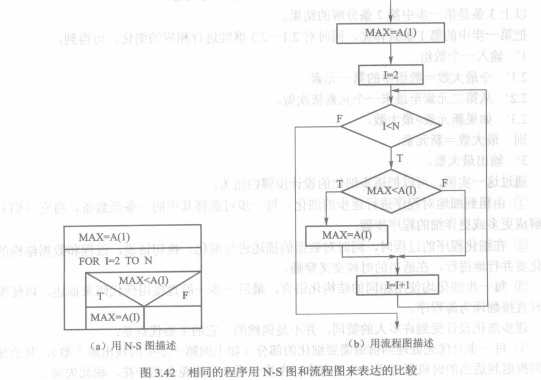
+ 伪代码和PDL语言
## 中篇 面向对象软件工程
### 第四章 面向对象与UML
面向对象是以问题空间中出现的物体为中心进行模型化的一种技术。
UML则是OO软件工程使用的统一建模语言。它是一种图形化的语言,主要用图形方式来表示。
由于从C++到java,笔者已经多次接触面向对象的概念,面向对象的内容将较为简略。
#### 4.1 面向对象概述
面向对象技术通过抽象化现实世界种的物体,来描述一个系统。
##### 4.1.1 对象和类
对象和类是面向对象技术的核心。对象代表客观世界中实际或抽象的事务。而类则是对于一组客观对象的抽象。
在计算机世界中,类是一种提供具有特定功能的模块和一种代码共享的手段或工具。
类和对象的关系可以看成是抽象和具体的关系。
##### 4.1.2 面向对象的基本特性
1. 抽象
2. 封装
3. 继承
4. 多态
##### 4.1.3 面向对象开发的优点
1. 提高软件系统的可复用性
2. 提高软件系统的可扩展性
3. 提高软件系统的可维护性
#### 4.2 UML简介
UML代表了OO软件开发技术的发展方向。
##### 4.2.1 UML的组成
UML是一种基于面向对象的可视化建模语言。提供了丰富的以图形符号表示的模型元素,这些标准的图形符号隐含了UML的语法,而这些图形符号组成的模型给出了语义。
1. UML的模型元素
UML定义了两类模型元素,一类模型元素用于表示模型中的某个概念,如类、对象、构件、用例、结点(node)、接口、包和注释等,另一类用于表示模型间相互联系的关系,关系主要有关联、泛化、依赖、实现、聚集和组合。
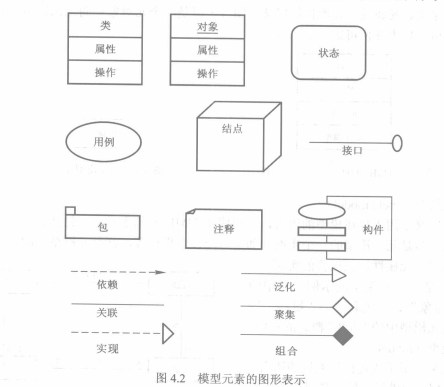
几种主要连接关系的含义——对于这六种连接关系,需要了解其对应图示和对应的代码表示:
+ 关联(association):模型元素实例间的固定对应关系,永久性
+ 泛化(generalization):表示一般与特殊关系,一般元素是特殊元素的泛化(代码中表现为特殊元素**继承**一般元素)
+ 依赖(dependency):一个元素依赖于另一个元素,为短暂性关系。
+ 实现(realization):表示接口和实现它的模型之间的关系。**代码中表现为虚函数的实现。**
+ 聚集(aggregation):整体与部分,例如鸟聚集形成鸟群
+ 组合(composition):强烈的整体与部分,例如轮胎是车的一部分,轮胎组合而形成车
2. UML的元模型结构
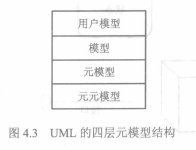
+ 元元模型(meta-meta model):任何模型的基础,概念非常难解释,或许可以理解为元模型的抽象
+ 元模型(meta model):定义了用于描述模型的语言,例如类、属性、操作都是元模型层的元对象。
+ 模型(model):是对现实世界(问题领域/解决方案)的抽象

+ 用户模型(user model):模型的实例,用于表达一个模型的特殊情况

3. 图和视图
+ 图(diagram)
+ 静态图(static diagram):用例图、类图、对象图、构件图、部署图
+ 动态图(dynamic diagram):状态图、时序图、协作图、活动图
+ 视图(view)
+ 用例视图(use case view):用户视角看到系统应有的外部功能
+ 逻辑视图(logical view):系统的静态结构
+ 进程视图(process view):系统的动态行为
+ 构件视图(component view):系统实现的结构和行为特征
+ 部署视图(deployment view):系统的实现环境和构件被部署到物理结构的映射
##### 4.2.2 UML的特点
1. 统一标准
2. 面向对象
3. 表达能力强大、可视化
##### 4.2.3 UML的应用
UML适用于以面向对象技术来描述的任何系统,而且适用于系统开发的不同阶段。
还可以作为测试阶段的依据。
#### 4.3 静态建模
UML的静态建模机制包括用例图、类图和对象图
##### 4.3.1 用例图与用例模型
用例模型用于把应满足用户需求的基本功能聚合起来表示。
用例模型由一组用例图构成,其基本组成部件是用例、参与者和系统。用例图可以描述软件系统和外部参与者(actor)之间的监护,一个用例代表从外部可见的系统的一个功能。
1. 组成符号
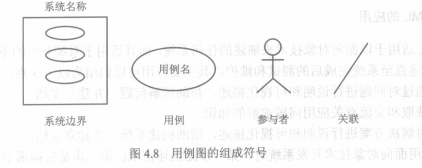
2. 建立用例图
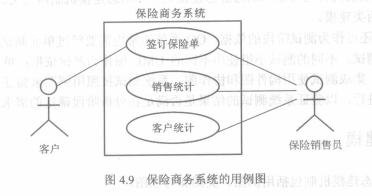
3. 用例之间的关系
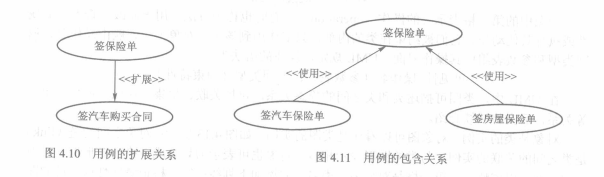
用例之间存在两种关系
+ 扩展关系(extend)
一个用例中可能加入另一个用例的动作。
+ 包含关系(include)
一个用例的行为包含另一个用例的行为。
##### 4.3.2 类图和对象图
类和对象模型揭示了系统的静态结构,在UML中,类和对象模型分别由类图和对象图表示
1. 类图和对象图
类图描述同类对象的属性和形为,类图可表示类和类之间的关系,在UML中,类一般表示为一个划分成3格的矩形框,下面的两格可以进行省略。第一格指定类的名字。第二格为类的属性,第三格为类的操作。

类种表示属性的语法为:可见性 属性名:类型 = 默认值(约束特性)
常用的可见性有Public、Private和Protected这3种,在UML种分别表示为+、-和#
类中表示操作的语法为:可见性 操作名(参数表): 返回类型(约束特性)
类图可描述类与类之间的静态关系。对象图则是类图的实例,对象图的对象名下面要加上下划线,常用于表达复杂的类图的一个实例。
2. 关联关系
+ 普通关联:最常见的关联,两个类之间用一条直线连接
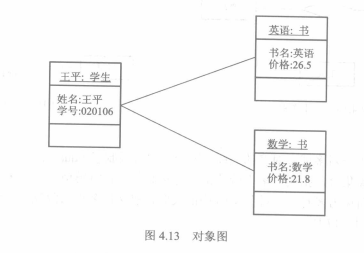
关联的两端可以协商一个被称为重数的数值范围

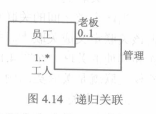
+ 递归关联:一个类和自身关联
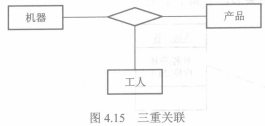
+ 多重关联:两个以上的类之间互相关联
+ 有序关联:在多的关联端的对象可以是一个无序集合,如果该集合有序,可以加上{ordered}来指明
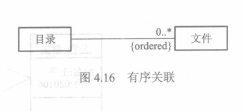
+ 限制关联:用于一对多或多对多的关联,将一端的多通过**限制子**简化为1
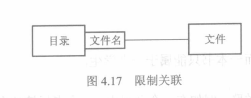
+ 或关联:例如房产只能归属于个人或公司中的一方
+ 关联类:当两个类之间的关联重数是多对多时,可以把该关联定义成关联类。
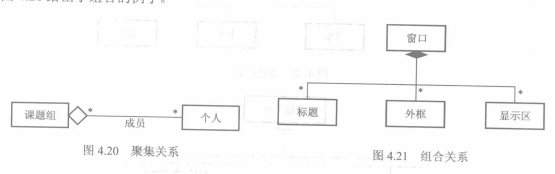
3. 聚集关系
**聚集是一种特殊形式的关联。**表示类之间具有整体与部分的关系。有一种特殊的聚集称为组合。
聚集表示为空心菱形。组合表示为实心菱形。
1. 聚集:“部分”对象可以是“整体”对象的一部分。
2. 组合:“整体”强烈拥有部分。
4. 泛化
泛化也称为继承。例:飞兽和走兽泛化为动物。
UML对泛化的3个要求:
+ 一般元素所具有的关联、属性和操作。特殊元素也都隐含性地具有。
+ 特殊元素应包含额外信息。
+ 允许使用特殊元素实例的地方,也应能使用一般元素。
1. 普通泛化
表示为一端带空心三角形的连线。空心三角形紧挨着父类,子类则继承父类的属性、操作和所有的关联关系。
2. 限制泛化
在泛化关系上附加一个约束条件,以便于进一步说明泛化关系的使用方法或扩充方法。预定义约束有四种:多重、不相交、完全和不完全。
5. 依赖
假设有两个元素X、Y,如果修改X的定义会引起对Y的定义的修改,则称元素Y依赖于X。例如某个类中使用另一个类的对象作为操作中的参数。依赖关系表示为带箭头的虚线。
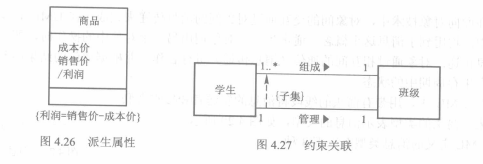
6. 约束与派生
约束包含或关联、有序关联等。
派生则用于描述某种事物的产生规则:例如人的年龄可以由出生日期和当前日期派生出。
约束和派生一般用花括号括起来放在模型元素旁边,或者用圆括号括起来以注释的方式与模型元素相连。
##### 4.3.3 包
OO设计中,可以把许多类集合成一个更高层次的单位,形成一个高内聚,低耦合的类的集合。这种分组机制在UML中称为包。
包与包之间可以有关系,允许的关系有:依赖和泛化。
#### 4.4 动态建模
UML不仅能够描述系统静态结构,也提供了描述系统动态行为的图形工具:状态图、时序图、协作图和活动图等。
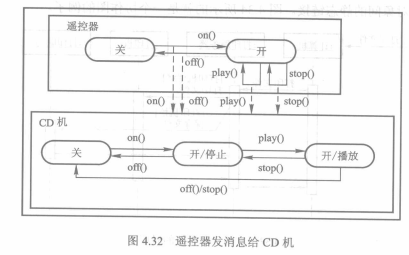
##### 4.4.1 消息
UML中,用带有箭头的线段将消息的发送者和接收者联系起来,箭头的类型表示消息的类型:
 1. 简单消息(simple message):表示简单的控制流。用于描述控制是如何在对象间进行传递的,而不考虑通信的细节。
2. 同步消息(synchronous message):表示嵌套的控制流。操作的调用是一种典型的同步消息。调用者发送消息后必须等待消息返回,才可继续执行自己的操作。
3. 异步消息(asynchronous message):表示异步控制流。调用者发送消息后,不用等待消息的返回即可继续执行自己的操作。
##### 4.4.2 状态图
状态图(state diagram)用来描述一个特定对象的所有可能状态以及引起其状态转移的事件。
1. 状态
状态是对象执行了一系列活动的结果。某个事件发生后,对象的状态将发生变化,从一个状态转移到另一个状态。
状态图有初态、终态与中间状态3种状态。一个状态图只能有一个初态,终态则可以有多个。
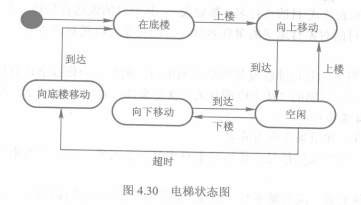
一个状态由状态名、状态变量和活动3个部分组成。状态变量和活动是可选的。前者表示对象在该状态时的属性值,后者表示该状态时要执行的操作。

2. 状态转移
对象从一种状态改变成另一种状态称为状态转移。状态图中用带箭头的连线表示。状态转移的表示格式一般为: 事件说明 [守卫条件]/动作表达式^发送子句
+ 事件说明(event_signature)由事件名后接用括号括起来的参数表组成。
+ 守卫条件(guard_condition)是一个布尔表达式,如果一个转移中间同时有守卫条件和事件说明,则当前仅当条件为真且事件发生时状态转移才会发生。
+ 动作表达式(action_expression)是一个触发状态转移时可执行的过程表达式。多个动作表达式之间用“/”分割。
+ 发送子句(send_clause)是动作的一个特例,它被用来在两个状态转移之间发送消息。
3. 事件
事件是指已经发生的且可能触发某些活动的事情。例如按下计算机的电源开关时,计算机开始启动。“按下电源开关”就是事件,事件触发的活动是“开始启动”。
UML中4类事件:
+ 条件变真:守卫条件变为成立
+ 收到另一个对象的信号
+ 收到其他对象或对象本身的操作调用
+ 经过指定的时间间隔
4. 状态图之间发送消息
状态图可以给其他状态图发送消息。可以通过动作(在发送子句指定接收者)或者状态图间用虚线箭头表示。后者必须用矩形框把状态图中所有对象组合在一起。
##### 4.4.3 时序图和协作图
1. 时序图
时序图(sequence diagram)用来描述对象之间的动态交互。体现对象间消息传递的时间顺序。它以垂直轴表示时间,水平轴表示不同的对象。
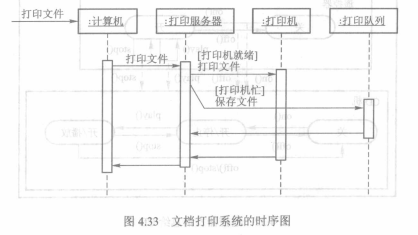
时序图中的消息可以是信号(signal)或操作调用。收到消息时,接收对象即开始活动,表名对象被激活,通过在对象生命线上显示一个细长矩形框来表示激活。
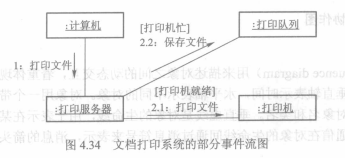
2. 协作图
协作图(collaboration diagram)用于描述相互协作的对象间的交互和链接。虽然时序图也可用来描述对象间的交互,但侧重点不同。时序图着重于时间顺序,协作图着重于对象之间的连接。
##### 4.4.4 活动图
活动图(activity diagram)显示动作流程及其结果,它既可以用来描述操作(类的方法)的行为,也可以描述用例和对象内部的工作过程。活动图是由状态图变化而来的,它们各用于不同的目的。
活动图中动作状态之间的迁移不是靠事件触发,活动图中一个活动结束后就将立即进入下一个活动。
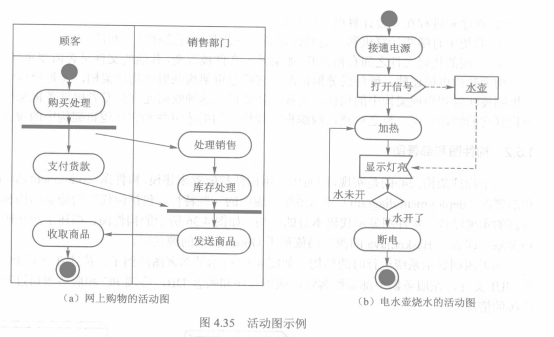
1. 活动和转移
活动有一个起点,但可以有多个终点。起点用黑圆点表示。终点用黑圆点外加一个小圆圈表示。活动间转移允许有守卫条件、发送子句和动作表达式,语法与状态图中的定义相同。
2. 泳道
泳道表达了该项活动由谁完成。泳道用矩形框来表示,属于某一泳道的活动放在该矩形框内,将对象名放在矩形框顶部,表示泳道中的活动由该对象负责。
3. 对象
对象可以作为活动的输入或输出,输入输出关系用虚线箭头表示。
4. 信号
活动图可以表示信号的发送与接收,分别用发送和接收标志来表示。
以上四种UML的动态图中,各自侧重点不同,分别用于不同的场合。
时序图和协作图比较适合描述单个用例中几个对象的行为。
### 第五章 需求工程与需求分析
#### 5.1 软件需求工程
##### 5.1.1 软件需求的定义
> 软件需求主要指一个软件系统必须遵循的条件或具备的能力。
软件需求一般包括三个不同的层次:
+ **业务需求**。客户或市场的高层次目标要求。
+ **用户需求**。从用户使用角度描述软件产品必须完成的任务。一般用用例模型文档描述。
+ **功能需求**。定义软件开发人员必须实现的软件功能。是用户需求在系统上的具体反应,思考的角度从用户转换到了开发者。
##### 5.1.2 软件需求的特性
软件需求包括以下六个特性:
+ 功能性
+ 可用性
+ 可靠性
+ 性能
+ 可支持性
+ 设计约束
#### 5.2 需求分析与建模
需求分析通常指软件开发的第一项活动,而该活动的目的主要是为待开发的软件系统进行需求定义与分析,并建立一个需求模型(requirement model)。
##### 5.2.1 需求分析的步骤
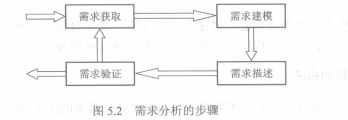
软件需求分析一般包括如上图的四个步骤:
+ 需求获取,从分析当前系统包含的数据开始。需要与用户交流,从用户收集功能需求,在考虑对质量要求和是否可复用已有软件。
+ 需求建模,主要任务是建立需求模型,图形化模型是可视化地说明软件需求的最好手段。常用模型:用例图、数据流图、实体联系图、控制流图、状态转换图。
+ 需求描述(即编写SRS),任务是编写软件需求规格说明书(SRS),必须使用统一格式的文档进行描述。编写SRS应该指明需求来源并为每项需求注上标号。
+ 需求验证:确保需求规格说明书可作为软件设计和最终系统验收的依据。
从图中可以看出,需求分析是迭代过程,4步周而复始直到SRS符合用户需求。
#### 5.4 需求模型
##### 5.4.1 需求模型概述
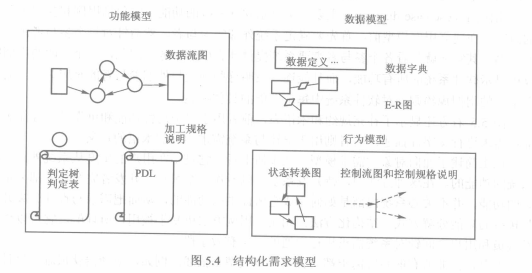
1. 结构化需求模型
该模型主要由三部分组成:包括数据流图和加工规格说明的**功能模型**、主要由数据字典和E-R图等组成的**数据模型**、由状态转换图、控制流图和控制规格说明等组成的**行为模型**。
2. 面向对象需求模型
面向对象需求模型由三个部分组成:用例模型、补充规约和术语表。
用例图(use case diagram)主要用于显示软件系统的功能。包括用例和参与者两方面的内容。一个全面的用例图不仅可显示软件系统的所有功能,且能逐一表名这些功能与外部参与者的对应关系。
用例图中每个用例对应一个用例规约,文字性描述一个用例。
此外还有补充规约和术语表辅助描述该需求模型。
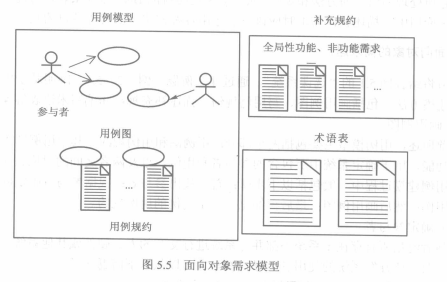
本质上看,需求模型是站在用户的角度从系统外部来描述系统的功能的。
##### 5.4.2 面向对象的需求建模
课本(《软件工程:原理、方法与应用》)该章节通过一个实例讲述了从需求中建立需求模型的过程。如果初学,可跟随课本过程进行学习,实验课和大作业也完成了该过程。限于篇幅本笔记不会完整的描述一个需求建模的过程,笔者将尽力用自己的语言进行总结。
面向对象的需求建模分为4步:
+ 画用例图
要画出用例图,要先从需求中确定本系统的参与者(存在于系统外部,与系统进行交互的人、硬件或其它系统),然后根据需求中需要实现的功能确定每个参与者相关的用例。
+ 写用例规约
对于每个用例撰写用例规约。用例规约包含:
+ 简要说明(brief description)
+ 事件流(flow of event)
+ 特殊需求(special requirement)
+ 前置条件(pre-condition)和后置条件(post-condition)
+ 描述补充规约,对全局进行一些描述
+ 编写术语表
#### 5.5 软件需求描述
软件需求规格说明书简称SRS,是软件开发人员在分析阶段需要完成的用于描述需求的文档。
SRS包括引言、信息描述、功能描述、行为描述、质量保证、接口描述和其他描述等内容。
### 第六章 面向对象分析
#### 6.1 软件分析概述
用户一般只会注重软件的外在表现,也就是所谓的软件需求。而开发者更关注软件的内部逻辑结构,就一般称之为**软件分析**。
##### 6.1.1 面向对象软件分析
在软件分析模型中,普遍采用图形和自然语言相结合的表达法,并使用多种图形描述工具。第四章介绍的UML,就是面向对象分析(object-oriented analysiz, OOA)的重要表达工具。
1. OOA的主要任务
理解用户的需求,进行分析,提取类和对象,并结合分析进行建模。
2. OOA的模型
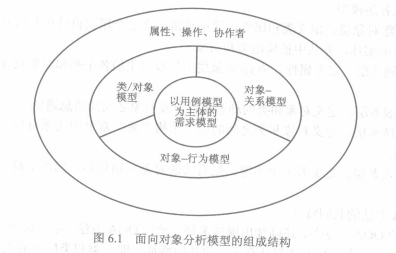
OOA模型核心是以用例模型为主题的需求模型。获得软件需求后,可以定义如图所示的三种子模型。
##### 6.1.2 面向对象分析模型
软件工程领域已经涌现了众多的OOA方法。
1. 典型的五层次模型
最典型的为Coad和Yourdon的OOA方法,通过下列的步骤来建立各层模型
+ 建立类/对象层
+ 建立属性层
+ 建立服务层
+ 建立结构层
+ 建立主题曾
2. OOA方法的共同特征
其他不同的OOA方法也通常具有相似的建模步骤:
+ 需求理解
+ 定义类和对象
+ 标识对象的属性和操作
+ 标识类的结构和层次
+ 建立对象-关系模型
+ 建立对象-行为模型
+ 评审OOA模型
3. OOA模型在软件开发中的地位
面向对象软件开发过程如图所示
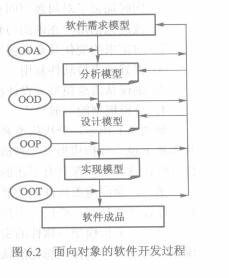
面向对象的开发全过程其实是OOA、OOD、OOP和OOT的迭代过程。
#### 6.2 面向对象分析建模
如同需求分析,课本会通过一个样例较为详细和直观的展现面向对象分析的内容,笔者仅在此处作过程和知识点总结。
##### 6.2.1 识别与确定分析类
文字说明的软件需求过渡到图形描述的分析模型,是一个渐进的过程。确定分析类是这个过程的第一步。
1. 分析类的类型
分析类被划分为3种类型:**边界类**、**控制类**和**实体类**,分别用标记\<\\>、\<\\>和\<\\>标识。
+ 边界类是对参与者或外部交互协议的接口。一个系统可能有多种边界类
+ 用户界面类
+ 系统接口类
+ 设备接口类
+ 控制类用于封装一个或几个用例所特有的流程控制行为。
+ 实体类用于对必须存储的信息和相关的行为建模。主要职责是储存和管理系统中的信息。通常具有持久性。
2. 查找分析类
这个过程通常以每一个用例作为研究对象,确定它的边界类、控制类和实体类,画出它的简单类图。一般的,一个参与者对应一个边界类。
##### 6.2.2 建立对象-行为模型
这个过程中一般会根据用例规约绘制用例的动态图。这之中又包括时序图和协作图。
1. 时序图
时序图按时间顺序描述系统元素间的交互。时序图中需要有这个用例出的参与者、边界类对象、控制类对象、实体类对象,这四类对象按序加入,因为每个用例都应当是参与者触发的,按顺序依次调用各类图。
按笔者的实际体会感受来说,时序图的绘画并没有什么技巧可言,按照你对用例的理解,把每次消息传递当作:“调用这个类的一个方法”看待,画图即可。
2. 协作图
协作图按照空间和时间的顺序描述系统元素之间的交互及相互关系。
协作图也可以由时序图直接转换而得到。
3. 为分析类分配职责
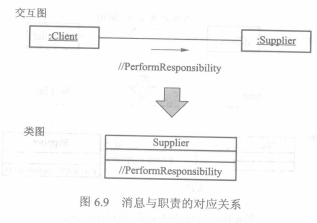
该段文字的含义与我在时序图末尾的个人感受基本一致。一条消息的接收者通过承担响应的职责(这里还不是一个类的操作,但投射到软件设计中就是类中需要有这个方法)来作为对消息发出者的回应。
4. 状态图
类涉及的用例行为比较复杂时会创建一个状态图
##### 6.2.3 建立对象-关系模型
上节讨论的对象-行为模型又称为动态模型。本节介绍的对象-关系模型就是静态模型。主要涉及类的属性、分析类的关联、分析类图和分析类的合并等内容。
1. 分析类的属性
分析类本身具有的信息。类可以用属性来储存信息。
2. 分析类的关联
分析类具有指向其他分析类的关联,通过这种关联能够找到其他分析类。
3. 分析类图
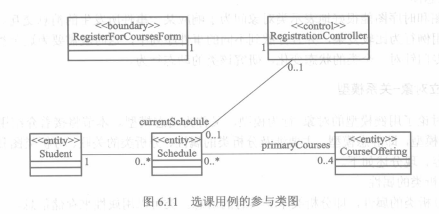
分析类图用于表现分析类及其关系,其中描述某个用例的分析类图称为参与类图(view of participating)。逻辑上,每个用例对应一张完整的参与类图。
4. 分析类的合并
对于整个系统而言,需要合并分析类,把具有相似行为的类合并为一个。每当更新一个类,就要更新或补充用例规约,必要时更新原始需求。
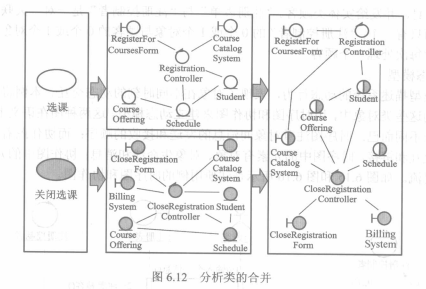
### 第七章 面向对象设计
面向对象设计的任务是将分析阶段建立的分析模型转变为软件设计模型。面向对象分析与面向对象设计之间的界限表面上很不明显。
#### 7.1 软件设计概述
##### 7.1.1 软件设计的概念
设计的目标是细化解决方案的可视化模型,确保设计模型最终能平滑过渡到程序代码。
分析模型和设计模型有许多相似之处,但目的有本质区别。分析模型强调软件“应该做什么”,设计模型要回答“该怎么做”的问题,要给出解决问题的全部解决方案,当设计模型完成后,编程人员便可以进行编程了。
软件设计已经形成了一系列基本概念,称为各种设计方法的基础:
+ 模块与构件
模块(module)的概念由来已久。汇编语言中的子程序、FORTRAN语言中的辅程序、Pascal语言中的过程、Java语言中的类都是模块的实例。
> 模块是一个拥有明确定义的输入、输出和特性的程序实体。
广义地说,对象也是一种模块,模块设计中要求的高耦合,低内聚(详细介绍于7.1.3),在对象设计中依旧适用。而可重复使用的软件组件就被称为软件构件(software component)。
+ 抽象与细化
软件规模不断增大,设计复杂性也不断增大,抽象(abstraction)便成了控制复杂性的基本策略之一。软件工程是一种层次化技术,抽象也是分层次的。传统软件工程的数据流图就体现了抽象的思想,最高层抽象程度最高。层次越低,越能看到各种细节。
软件设计不断降低抽象级别的过程,就是细化(refinement)。
+ 信息隐藏
+ 软件复用
##### 7.1.2 软件设计的任务
软件设计一般包括数据设计、体系结构设计、接口设计和过程设计等内容,一般分为两个阶段
+ 概要设计:包括结构设计和接口设计,并编写概要设计文档
+ 详细设计:确定各个软件部件的数据结构和操作,产生描述各软件部件的详细设计文档。
每个阶段完成的文档都必须经过复审
##### 7.1.3 模块化设计
模块化设计(modular design)的目的是按照规定把大型软件划分为一个个较小的、相对独立但相互关联的模块。
**分解**和**模块独立性**是实现模块设计的重要思想:
1. 分解
分解(decomposition)是处理复杂问题常用的方法。OO软件工程中靠分解来划分类和对象。把复杂的问题分解为几个较小的问题,能够减小解题需要的总工作量。
但要注意,无限的分下去,模块本身复杂度虽然变小,模块间的接口工作量却会增大,因此要控制模块大小在一个最小成本区。
2. 模块独立性
模块独立性(module independence)概括了把软件划分为模块时要遵守的准则,也是判断模块构造是否合理的标准。坚持模块的独立性,一般认为是获得良好设计的关键。
独立性可以从模块本身的**内聚**(cohesion)和模块之间的**耦合**(coupling)两个方面来度量。前者指模块内部各个成分之间的联系,所以也称为块内联系或模块强度。后者指模块和其他模块之间的联系。
1. 内聚
内聚是从功能的角度对模块内部聚合能力的量度。以下分为7类的模块,从左到右内聚能力逐步增强。

2. 耦合
耦合是对软件不同模块间联系的度量,同样分为7类:

耦合越弱,表名模块的独立性越强。但实际工作中,中等甚至较强的耦合不可能也不必完全禁用。但强耦合(一个模块直接调用另一个模块的数据等)应该尽量不用。
#### 7.2 面向对象设计建模
##### 7.2.1 面向对象设计模型
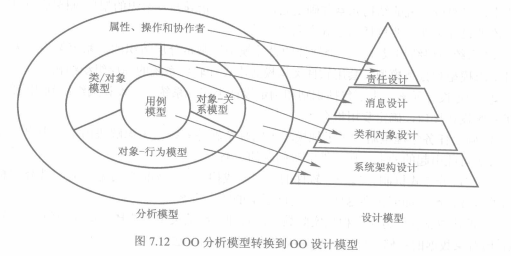
##### 7.2.2 面向对象设计的任务
OOD的软件设计也可划分为两个层次:系统架构设计和系统元素设计,分别由系统架构师(system architect)和软件设计师(software designer)完成。
1. 系统架构设计
软件系统架构指系统主要组成元素的组织或结构,以及其他全局性决策。主要包括以下六个方面的活动:
+ 系统高层结构设计
+ 确定设计元素(识别和确定设计类和子系统)
+ 确定任务管理策略
+ 实现分布式机制
+ 设计数据存储方案
+ 人机界面设计
2. 系统元素设计
系统元素包括组成系统的类、子系统与接口、包等。系统元素设计是对每一个设计元素进行详细的设计,包括以下设计内容
+ 类/对象设计
+ 子系统设计
+ 包设计
##### 7.2.3 模式的应用
为了利用已取得成功的设计结果和经验,提倡在面向对象设计中充分应用设计**模式**(pattern),这样做既可以减少工作量,也可以提高设计结果质量。
1. 模式的定义
> 模式是解决某一类问题的方法论,也是对通用问题的解决方案。
模式通常分为不同的领域,建筑领域有建筑模式,软件设计领域也有设计模式。当一个领域逐渐成熟时,自然会出现许多模式。
2. 软件模式的分类
+ 架构模式:标识软件系统的基本组织结构方案。它提供了一组预定义的子系统,指定它们的职责。常见的架构模式由层次架构模式、MVC架构模式等。
+ 设计模式:提供面向对象的具体设计问题的解决方案。《Design Pattern》一书中有23个常用的模式的介绍,可分为构件型、结构型和行为型三类,包括桥接模式、工厂模式、组合模式等。
+ 习惯用法:是指针对具体程序设计语言的使用模式。
#### 7.3 系统架构设计
##### 7.3.1 系统高层结构设计
进行具体元素设计之前,首先需要确定系统高层结构,为后续设计提供一个公共的基础方案。
设计系统高层结构时可以选用架构模式(layers,model-view-control,pipes and filters,blackboard等)作为模板来定义系统高层框架。
一种针对中大型软件的典型分层方法,包括4个层次:
+ 应用子系统层
+ 业务专用层
+ 中间件层
+ 系统软件层

##### 7.3.2 确定设计元素
主要工作是确定设计类、子系统以及子系统接口,并找出可能复用的元素。
1. 映射分析类到设计元素
2. 确定子系统:将系统分为若干个子系统,可以独立开发、配置或交付它们,也可以在一组分布式计算节点上独立部署它们。还可以在不破坏系统其他部分的情况下独立地进行更改。
3. 定义子系统接口
##### 7.3.3 任务管理策略
在软件设计必须考虑任务管理,以实现应用软件对多用户、多任务的支持,满足并行处理的需求。
##### 7.3.4 分布式实现机制
确定网络拓扑配置、将设计元素分配到网络节点,设计分布处理机制。
##### 7.3.5 数据存储设计
对于实例数据需要持久保存的类,需要设计一种统一存储、读取和修改数据的方法(持久层)。
##### 7.3.6 人机交互设计
设计阶段给出有关人机交互的所有系统成分,包括用户如何操作系统、系统显示信息等。
#### 7.4 系统元素设计
系统元素设计的终点在于如何实现相关的类、关联、属性与操作,定义实现时所需的对象的算法与数据结构。
##### 7.4.1 子系统设计
1. 将子系统行为分配给子系统元素
2. 描述子系统元素(创建一个或多个类图/状态图)
##### 7.4.2 分包设计
1. 将设计元素划分到不同的包
2. 描述包之间的依赖关系
3. 避免包之间的互相依赖,同时保证复用价值高的包不要依赖复用价值低的包
##### 7.4.3 类/对象设计
类、对象设计是设计工作的核心。
主要考虑三个问题:
+ 如何实现分析模型中的边界类、实体类和控制类
+ 解决类设计中的实现问题时如何应用设计模式
+ 系统架构中的全局性觉得如何在类设计中体现
类图的设计过程用文字描述过于复杂,也过于抽象。笔者在此不再赘述。软件工程大作业和实验课都有设计类图的项目,也可以根据课本7.5章的实例了解。
类图的设计一般依赖于时序图,在设计好类的属性和方法后,还需要定义类之间的依赖关系。
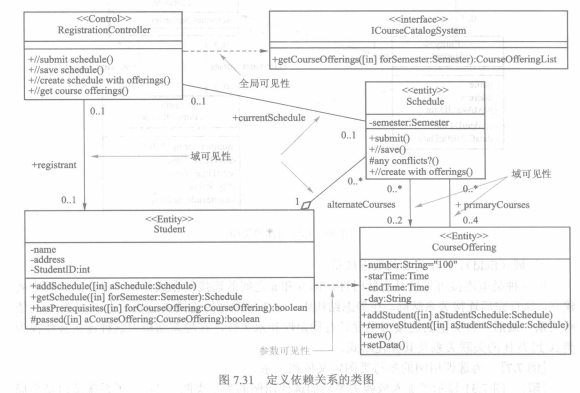
设计类还应该加以改进来处理适应编程语言、提高性能、处理错误等非功能性需求。
### 第八章 编码与测试
#### 8.1 编码概述
编码(coding)俗称编程序,编码阶段产生可执行的代码,把软件的需求真正付诸实现。编码阶段也称为实现(implementation)阶段。
##### 8.1.1 编码的目的
编码目的是使用选定的程序设计语言,把设计模型翻译为用该语言书写的源程序。

程序员需要养成良好的编码的风格,而且要十分熟悉使用的语言。
##### 8.1.2 编码的风格
传统程序设计十分强调编码风格(coding style,又称程序设计风格)。程序的目标是在清晰的前提下才追求效率。
+ 先求正确而后求快
+ 先求清楚而后求快
+ 求快不忘保持程序正确
+ 保持程序简单以求快
+ 书写清楚,不要为“效率”牺牲清楚
从控制结构、代码文档化和输入三个方面可以简述编码风格的要求:
+ 使用标准的控制结构
遵循模块逻辑中采用单入口、单出口标准结构这一主要原则,确保翻译出来的程序清晰可读。
+ 实现源代码的文档化
为了提高代码的可维护性,源代码也要实现文档化(code documentation),这主要包括以下三个方面的内容:
+ 有意义的变量名称
+ 适当的注释
+ 标准的书写格式
+ 满足用户友好的输入输出风格
程序的允许要充分考虑人的因素,尽量做到对用户友好(user friendly)
#### 8.2 编码语言与编码工具
分为基础语言、结构化语言、面向对象语言。
计算机专业的学生自大学以来已经大量了解这方面知识,此处略过。
#### 8.4 测试的基本概念
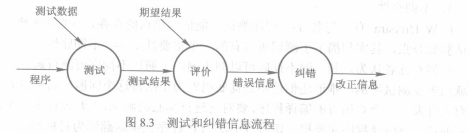
软件测试(software testing)是动态查找程序代码中的各类错误和问题的过程。
##### 8.4.1 目的与任务
测试(testing)的目的与任务:
+ 目的:发现程序的错误
+ 任务:通过在计算机上执行程序,暴露程序中潜在的错误
纠错(debugging)的目的与任务:
+ 目的:定位和纠正错误
+ 任务:消除软件故障,保证程序的可靠运行
##### 8.4.2 测试的特性
1. 挑剔性:抱着为证明程序有错的目的去测试
2. 复杂性:做好一个大型程序的测试,其复杂性不亚于对这个程序的开发
3. 不彻底性:不能证明错误不存在
4. 经济性:要根据重要程度决定测试的投入
##### 8.4.3 测试的种类

##### 8.4.4 测试的文档
一个程序所需的测试用例可以定义为:测试用例={测试数据+期望结果}
而测试结果则为:测试结果={测试数据+期望结果+实际结果}
#### 8.5 黑盒测试和白盒测试
在过去几十年中,软件测试的基本技术没有大的变化。
##### 8.5.1 黑盒测试
黑盒测试就是根据被测试程序功能来进行测试,所以也成为功能测试。有以下几种常用技术。
1. 等价分类法(equivalence partitioning)
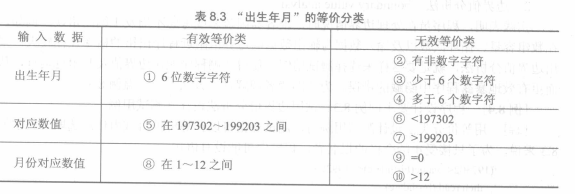
把输入数据的可能值分为若干等价类,使每类中的任何一个测试用例,都能代表统一等价类中的其他测试用例。即用少量代表性的例子来代替大量内容相似的测试。
划分等价类不仅要考虑有效等价类,还要考虑无效等价类。若干个无效等价类的测试用例不能合并。
2. 边界值分析法(boundary value analysis)
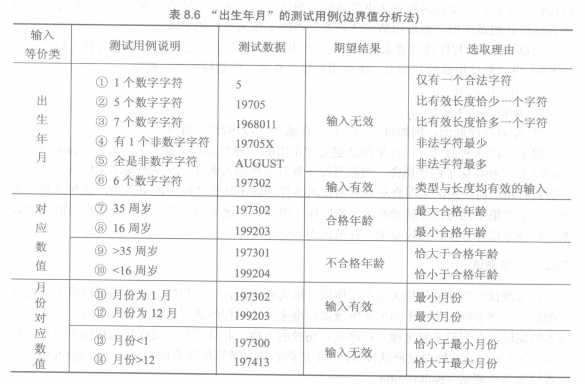
由于程序员处理边界情况时常常发生疏忽,因此在边界值附近程序出错概率较大。等价分类法的测试数据在各个等价类允许的值域内任意选取,而边界值分析的测试数据必须在边界值附近选取。
3. 错误猜测法
猜测被测程序在哪些地方容易出错,更多地依靠测试人员的直觉与经验。一般用猜错法补充一些例子作为辅助的手段。
此外还有种名为**因果图**法的方法,比较高明,但操作步骤较为复杂,不介绍详情。
##### 8.5.2 白盒测试
以程序的结构为依据,又称为结构测试。
早期白盒测试把注意力放在流程图各个判定框,称为逻辑覆盖测试(logic coverage testing),现在则用程序图替代流程图,称为路径测试(path testing)。
1. 逻辑覆盖测试法
通用流程图来设计测试用例,考察的重点是图中的判定框。

2. 路径测试法
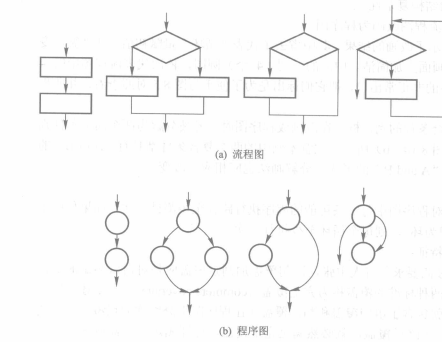
逻辑覆盖测试忽略了程序的执行路径。路径测试离不开**程序图**(program praph)。
程序图实际上是一种简化了的流程图,它是用来考察测试路径的有用工具。程序图保留了控制流的全部轨迹,舍弃了各框的细节。
+ 顺序执行的多个节点可以合并成一个节点
+ 符合条件的判定框,应该先分解成几个简单条件判定框,再画程序图
路径测试就是对程序图种每一条可能的程序执行路径至少测试一次。路径覆盖包含了点覆盖和边覆盖。
而对于安排循环测试,对于单循环结构的路径测试可以包括:
+ 零次循环
+ 一次循环
+ 最大值次循环
多重嵌套循环种,测试路径也应该跟随程序的实际需要来选择。
**选择测试路径的原则**:
+ 尽量选择具有功能含义的路径
+ 尽量用短路径代替长路径
+ 上一条测试路径到下一条从测试路径,尽量减少变动的部分
+ 由简入繁,如果可能先考虑不含循环
+ 不要选取没有明显功能含义的复杂路径
#### 8.6 测试用例设计
与往常一样,如果需要查看具体样例,请查看课本,带上具体样例,基本无可省略。
黑盒测试用例的设计往往会结合等价类、边界值法、猜错法三种方法进行样例设计,而之后则可以用白盒法验证产生的测试用例的充分性。
可以先采用等价分类法,再采用边界值法,但有时反过来效果更好。猜错法一般作为补充使用。
#### 8.7 多模块程序的测试策略
##### 8.7.1 测试的层次性
按照软件工程的观点,多模块程序的测试共包括4个层次。

+ 单元测试:应在编码阶段完成。单元一般以模块或子程序为单位。是测试的基础。单元测试发现错误约占总错误数的65%。
+ 集成测试:将经过单元测试的模块逐步组装成具有良好一致性的完整的程序。
+ 确认测试:
+ 有效性测试(黑盒测试):确认组装完毕的程序是否满足软件需求规格说明书(SRS)的要求。
+ 验收测试:主要由用户进行,可以进行几个星期或者几个月
+ $\alpha$与$\beta$测试:前者在受控环境下,用户在开发者的指导下进行测试。开发者负责记录错误和使用中的问题。后者由最终用户在自己的场所进行,问题由用户记录,不定期汇报给开发者。
+ 系统测试:更大范围的测试,系统可能包括硬件和原有其他软件,是验收工作一部分。
## 下篇 软件工程的近期进展、管理与环境
### 第九章 软件维护
> 软件维护是指软件系统交付使用以后,为了改正或满足新的需要而修改软件的过程。
#### 9.1 软件维护的种类
+ 完善性维护(perfective maintenance)
在使用期间不断改善和加强产品的功能与性能。整个维护工作量中,完善性维护约占50%~60%,居于第一位。
+ 适应性维护(adaptive maintenance)
指软件适应允许环境的改变而进行的一类维护。约占维护工作量25%。
+ 纠错性维护(corrective maintenance)
目的在于纠正在开发期间未能发现的遗留错误。约占维护工作量20%。
1. 简单消息(simple message):表示简单的控制流。用于描述控制是如何在对象间进行传递的,而不考虑通信的细节。
2. 同步消息(synchronous message):表示嵌套的控制流。操作的调用是一种典型的同步消息。调用者发送消息后必须等待消息返回,才可继续执行自己的操作。
3. 异步消息(asynchronous message):表示异步控制流。调用者发送消息后,不用等待消息的返回即可继续执行自己的操作。
##### 4.4.2 状态图
状态图(state diagram)用来描述一个特定对象的所有可能状态以及引起其状态转移的事件。
1. 状态
状态是对象执行了一系列活动的结果。某个事件发生后,对象的状态将发生变化,从一个状态转移到另一个状态。
状态图有初态、终态与中间状态3种状态。一个状态图只能有一个初态,终态则可以有多个。

一个状态由状态名、状态变量和活动3个部分组成。状态变量和活动是可选的。前者表示对象在该状态时的属性值,后者表示该状态时要执行的操作。

2. 状态转移
对象从一种状态改变成另一种状态称为状态转移。状态图中用带箭头的连线表示。状态转移的表示格式一般为: 事件说明 [守卫条件]/动作表达式^发送子句
+ 事件说明(event_signature)由事件名后接用括号括起来的参数表组成。
+ 守卫条件(guard_condition)是一个布尔表达式,如果一个转移中间同时有守卫条件和事件说明,则当前仅当条件为真且事件发生时状态转移才会发生。
+ 动作表达式(action_expression)是一个触发状态转移时可执行的过程表达式。多个动作表达式之间用“/”分割。
+ 发送子句(send_clause)是动作的一个特例,它被用来在两个状态转移之间发送消息。
3. 事件
事件是指已经发生的且可能触发某些活动的事情。例如按下计算机的电源开关时,计算机开始启动。“按下电源开关”就是事件,事件触发的活动是“开始启动”。
UML中4类事件:
+ 条件变真:守卫条件变为成立
+ 收到另一个对象的信号
+ 收到其他对象或对象本身的操作调用
+ 经过指定的时间间隔
4. 状态图之间发送消息
状态图可以给其他状态图发送消息。可以通过动作(在发送子句指定接收者)或者状态图间用虚线箭头表示。后者必须用矩形框把状态图中所有对象组合在一起。

##### 4.4.3 时序图和协作图
1. 时序图
时序图(sequence diagram)用来描述对象之间的动态交互。体现对象间消息传递的时间顺序。它以垂直轴表示时间,水平轴表示不同的对象。

时序图中的消息可以是信号(signal)或操作调用。收到消息时,接收对象即开始活动,表名对象被激活,通过在对象生命线上显示一个细长矩形框来表示激活。
2. 协作图
协作图(collaboration diagram)用于描述相互协作的对象间的交互和链接。虽然时序图也可用来描述对象间的交互,但侧重点不同。时序图着重于时间顺序,协作图着重于对象之间的连接。

##### 4.4.4 活动图
活动图(activity diagram)显示动作流程及其结果,它既可以用来描述操作(类的方法)的行为,也可以描述用例和对象内部的工作过程。活动图是由状态图变化而来的,它们各用于不同的目的。
活动图中动作状态之间的迁移不是靠事件触发,活动图中一个活动结束后就将立即进入下一个活动。

1. 活动和转移
活动有一个起点,但可以有多个终点。起点用黑圆点表示。终点用黑圆点外加一个小圆圈表示。活动间转移允许有守卫条件、发送子句和动作表达式,语法与状态图中的定义相同。
2. 泳道
泳道表达了该项活动由谁完成。泳道用矩形框来表示,属于某一泳道的活动放在该矩形框内,将对象名放在矩形框顶部,表示泳道中的活动由该对象负责。
3. 对象
对象可以作为活动的输入或输出,输入输出关系用虚线箭头表示。
4. 信号
活动图可以表示信号的发送与接收,分别用发送和接收标志来表示。
以上四种UML的动态图中,各自侧重点不同,分别用于不同的场合。
时序图和协作图比较适合描述单个用例中几个对象的行为。
### 第五章 需求工程与需求分析
#### 5.1 软件需求工程
##### 5.1.1 软件需求的定义
> 软件需求主要指一个软件系统必须遵循的条件或具备的能力。
软件需求一般包括三个不同的层次:
+ **业务需求**。客户或市场的高层次目标要求。
+ **用户需求**。从用户使用角度描述软件产品必须完成的任务。一般用用例模型文档描述。
+ **功能需求**。定义软件开发人员必须实现的软件功能。是用户需求在系统上的具体反应,思考的角度从用户转换到了开发者。
##### 5.1.2 软件需求的特性
软件需求包括以下六个特性:
+ 功能性
+ 可用性
+ 可靠性
+ 性能
+ 可支持性
+ 设计约束
#### 5.2 需求分析与建模
需求分析通常指软件开发的第一项活动,而该活动的目的主要是为待开发的软件系统进行需求定义与分析,并建立一个需求模型(requirement model)。
##### 5.2.1 需求分析的步骤

软件需求分析一般包括如上图的四个步骤:
+ 需求获取,从分析当前系统包含的数据开始。需要与用户交流,从用户收集功能需求,在考虑对质量要求和是否可复用已有软件。
+ 需求建模,主要任务是建立需求模型,图形化模型是可视化地说明软件需求的最好手段。常用模型:用例图、数据流图、实体联系图、控制流图、状态转换图。
+ 需求描述(即编写SRS),任务是编写软件需求规格说明书(SRS),必须使用统一格式的文档进行描述。编写SRS应该指明需求来源并为每项需求注上标号。
+ 需求验证:确保需求规格说明书可作为软件设计和最终系统验收的依据。
从图中可以看出,需求分析是迭代过程,4步周而复始直到SRS符合用户需求。
#### 5.4 需求模型
##### 5.4.1 需求模型概述
1. 结构化需求模型
该模型主要由三部分组成:包括数据流图和加工规格说明的**功能模型**、主要由数据字典和E-R图等组成的**数据模型**、由状态转换图、控制流图和控制规格说明等组成的**行为模型**。

2. 面向对象需求模型
面向对象需求模型由三个部分组成:用例模型、补充规约和术语表。
用例图(use case diagram)主要用于显示软件系统的功能。包括用例和参与者两方面的内容。一个全面的用例图不仅可显示软件系统的所有功能,且能逐一表名这些功能与外部参与者的对应关系。
用例图中每个用例对应一个用例规约,文字性描述一个用例。
此外还有补充规约和术语表辅助描述该需求模型。

本质上看,需求模型是站在用户的角度从系统外部来描述系统的功能的。
##### 5.4.2 面向对象的需求建模
课本(《软件工程:原理、方法与应用》)该章节通过一个实例讲述了从需求中建立需求模型的过程。如果初学,可跟随课本过程进行学习,实验课和大作业也完成了该过程。限于篇幅本笔记不会完整的描述一个需求建模的过程,笔者将尽力用自己的语言进行总结。
面向对象的需求建模分为4步:
+ 画用例图
要画出用例图,要先从需求中确定本系统的参与者(存在于系统外部,与系统进行交互的人、硬件或其它系统),然后根据需求中需要实现的功能确定每个参与者相关的用例。
+ 写用例规约
对于每个用例撰写用例规约。用例规约包含:
+ 简要说明(brief description)
+ 事件流(flow of event)
+ 特殊需求(special requirement)
+ 前置条件(pre-condition)和后置条件(post-condition)
+ 描述补充规约,对全局进行一些描述
+ 编写术语表
#### 5.5 软件需求描述
软件需求规格说明书简称SRS,是软件开发人员在分析阶段需要完成的用于描述需求的文档。
SRS包括引言、信息描述、功能描述、行为描述、质量保证、接口描述和其他描述等内容。
### 第六章 面向对象分析
#### 6.1 软件分析概述
用户一般只会注重软件的外在表现,也就是所谓的软件需求。而开发者更关注软件的内部逻辑结构,就一般称之为**软件分析**。
##### 6.1.1 面向对象软件分析
在软件分析模型中,普遍采用图形和自然语言相结合的表达法,并使用多种图形描述工具。第四章介绍的UML,就是面向对象分析(object-oriented analysiz, OOA)的重要表达工具。
1. OOA的主要任务
理解用户的需求,进行分析,提取类和对象,并结合分析进行建模。
2. OOA的模型

OOA模型核心是以用例模型为主题的需求模型。获得软件需求后,可以定义如图所示的三种子模型。
##### 6.1.2 面向对象分析模型
软件工程领域已经涌现了众多的OOA方法。
1. 典型的五层次模型
最典型的为Coad和Yourdon的OOA方法,通过下列的步骤来建立各层模型
+ 建立类/对象层
+ 建立属性层
+ 建立服务层
+ 建立结构层
+ 建立主题曾
2. OOA方法的共同特征
其他不同的OOA方法也通常具有相似的建模步骤:
+ 需求理解
+ 定义类和对象
+ 标识对象的属性和操作
+ 标识类的结构和层次
+ 建立对象-关系模型
+ 建立对象-行为模型
+ 评审OOA模型
3. OOA模型在软件开发中的地位
面向对象软件开发过程如图所示

面向对象的开发全过程其实是OOA、OOD、OOP和OOT的迭代过程。
#### 6.2 面向对象分析建模
如同需求分析,课本会通过一个样例较为详细和直观的展现面向对象分析的内容,笔者仅在此处作过程和知识点总结。
##### 6.2.1 识别与确定分析类
文字说明的软件需求过渡到图形描述的分析模型,是一个渐进的过程。确定分析类是这个过程的第一步。
1. 分析类的类型
分析类被划分为3种类型:**边界类**、**控制类**和**实体类**,分别用标记\<\\>、\<\\>和\<\\>标识。
+ 边界类是对参与者或外部交互协议的接口。一个系统可能有多种边界类
+ 用户界面类
+ 系统接口类
+ 设备接口类
+ 控制类用于封装一个或几个用例所特有的流程控制行为。
+ 实体类用于对必须存储的信息和相关的行为建模。主要职责是储存和管理系统中的信息。通常具有持久性。
2. 查找分析类
这个过程通常以每一个用例作为研究对象,确定它的边界类、控制类和实体类,画出它的简单类图。一般的,一个参与者对应一个边界类。
##### 6.2.2 建立对象-行为模型
这个过程中一般会根据用例规约绘制用例的动态图。这之中又包括时序图和协作图。
1. 时序图
时序图按时间顺序描述系统元素间的交互。时序图中需要有这个用例出的参与者、边界类对象、控制类对象、实体类对象,这四类对象按序加入,因为每个用例都应当是参与者触发的,按顺序依次调用各类图。
按笔者的实际体会感受来说,时序图的绘画并没有什么技巧可言,按照你对用例的理解,把每次消息传递当作:“调用这个类的一个方法”看待,画图即可。
2. 协作图
协作图按照空间和时间的顺序描述系统元素之间的交互及相互关系。
协作图也可以由时序图直接转换而得到。
3. 为分析类分配职责
该段文字的含义与我在时序图末尾的个人感受基本一致。一条消息的接收者通过承担响应的职责(这里还不是一个类的操作,但投射到软件设计中就是类中需要有这个方法)来作为对消息发出者的回应。

4. 状态图
类涉及的用例行为比较复杂时会创建一个状态图
##### 6.2.3 建立对象-关系模型
上节讨论的对象-行为模型又称为动态模型。本节介绍的对象-关系模型就是静态模型。主要涉及类的属性、分析类的关联、分析类图和分析类的合并等内容。
1. 分析类的属性
分析类本身具有的信息。类可以用属性来储存信息。
2. 分析类的关联
分析类具有指向其他分析类的关联,通过这种关联能够找到其他分析类。
3. 分析类图
分析类图用于表现分析类及其关系,其中描述某个用例的分析类图称为参与类图(view of participating)。逻辑上,每个用例对应一张完整的参与类图。

4. 分析类的合并
对于整个系统而言,需要合并分析类,把具有相似行为的类合并为一个。每当更新一个类,就要更新或补充用例规约,必要时更新原始需求。

### 第七章 面向对象设计
面向对象设计的任务是将分析阶段建立的分析模型转变为软件设计模型。面向对象分析与面向对象设计之间的界限表面上很不明显。
#### 7.1 软件设计概述
##### 7.1.1 软件设计的概念
设计的目标是细化解决方案的可视化模型,确保设计模型最终能平滑过渡到程序代码。
分析模型和设计模型有许多相似之处,但目的有本质区别。分析模型强调软件“应该做什么”,设计模型要回答“该怎么做”的问题,要给出解决问题的全部解决方案,当设计模型完成后,编程人员便可以进行编程了。
软件设计已经形成了一系列基本概念,称为各种设计方法的基础:
+ 模块与构件
模块(module)的概念由来已久。汇编语言中的子程序、FORTRAN语言中的辅程序、Pascal语言中的过程、Java语言中的类都是模块的实例。
> 模块是一个拥有明确定义的输入、输出和特性的程序实体。
广义地说,对象也是一种模块,模块设计中要求的高耦合,低内聚(详细介绍于7.1.3),在对象设计中依旧适用。而可重复使用的软件组件就被称为软件构件(software component)。
+ 抽象与细化
软件规模不断增大,设计复杂性也不断增大,抽象(abstraction)便成了控制复杂性的基本策略之一。软件工程是一种层次化技术,抽象也是分层次的。传统软件工程的数据流图就体现了抽象的思想,最高层抽象程度最高。层次越低,越能看到各种细节。
软件设计不断降低抽象级别的过程,就是细化(refinement)。
+ 信息隐藏
+ 软件复用
##### 7.1.2 软件设计的任务
软件设计一般包括数据设计、体系结构设计、接口设计和过程设计等内容,一般分为两个阶段
+ 概要设计:包括结构设计和接口设计,并编写概要设计文档
+ 详细设计:确定各个软件部件的数据结构和操作,产生描述各软件部件的详细设计文档。
每个阶段完成的文档都必须经过复审
##### 7.1.3 模块化设计
模块化设计(modular design)的目的是按照规定把大型软件划分为一个个较小的、相对独立但相互关联的模块。
**分解**和**模块独立性**是实现模块设计的重要思想:
1. 分解
分解(decomposition)是处理复杂问题常用的方法。OO软件工程中靠分解来划分类和对象。把复杂的问题分解为几个较小的问题,能够减小解题需要的总工作量。
但要注意,无限的分下去,模块本身复杂度虽然变小,模块间的接口工作量却会增大,因此要控制模块大小在一个最小成本区。
2. 模块独立性
模块独立性(module independence)概括了把软件划分为模块时要遵守的准则,也是判断模块构造是否合理的标准。坚持模块的独立性,一般认为是获得良好设计的关键。
独立性可以从模块本身的**内聚**(cohesion)和模块之间的**耦合**(coupling)两个方面来度量。前者指模块内部各个成分之间的联系,所以也称为块内联系或模块强度。后者指模块和其他模块之间的联系。
1. 内聚
内聚是从功能的角度对模块内部聚合能力的量度。以下分为7类的模块,从左到右内聚能力逐步增强。

2. 耦合
耦合是对软件不同模块间联系的度量,同样分为7类:

耦合越弱,表名模块的独立性越强。但实际工作中,中等甚至较强的耦合不可能也不必完全禁用。但强耦合(一个模块直接调用另一个模块的数据等)应该尽量不用。
#### 7.2 面向对象设计建模
##### 7.2.1 面向对象设计模型

##### 7.2.2 面向对象设计的任务
OOD的软件设计也可划分为两个层次:系统架构设计和系统元素设计,分别由系统架构师(system architect)和软件设计师(software designer)完成。
1. 系统架构设计
软件系统架构指系统主要组成元素的组织或结构,以及其他全局性决策。主要包括以下六个方面的活动:
+ 系统高层结构设计
+ 确定设计元素(识别和确定设计类和子系统)
+ 确定任务管理策略
+ 实现分布式机制
+ 设计数据存储方案
+ 人机界面设计
2. 系统元素设计
系统元素包括组成系统的类、子系统与接口、包等。系统元素设计是对每一个设计元素进行详细的设计,包括以下设计内容
+ 类/对象设计
+ 子系统设计
+ 包设计
##### 7.2.3 模式的应用
为了利用已取得成功的设计结果和经验,提倡在面向对象设计中充分应用设计**模式**(pattern),这样做既可以减少工作量,也可以提高设计结果质量。
1. 模式的定义
> 模式是解决某一类问题的方法论,也是对通用问题的解决方案。
模式通常分为不同的领域,建筑领域有建筑模式,软件设计领域也有设计模式。当一个领域逐渐成熟时,自然会出现许多模式。
2. 软件模式的分类
+ 架构模式:标识软件系统的基本组织结构方案。它提供了一组预定义的子系统,指定它们的职责。常见的架构模式由层次架构模式、MVC架构模式等。
+ 设计模式:提供面向对象的具体设计问题的解决方案。《Design Pattern》一书中有23个常用的模式的介绍,可分为构件型、结构型和行为型三类,包括桥接模式、工厂模式、组合模式等。
+ 习惯用法:是指针对具体程序设计语言的使用模式。
#### 7.3 系统架构设计
##### 7.3.1 系统高层结构设计
进行具体元素设计之前,首先需要确定系统高层结构,为后续设计提供一个公共的基础方案。
设计系统高层结构时可以选用架构模式(layers,model-view-control,pipes and filters,blackboard等)作为模板来定义系统高层框架。
一种针对中大型软件的典型分层方法,包括4个层次:
+ 应用子系统层
+ 业务专用层
+ 中间件层
+ 系统软件层

##### 7.3.2 确定设计元素
主要工作是确定设计类、子系统以及子系统接口,并找出可能复用的元素。
1. 映射分析类到设计元素
2. 确定子系统:将系统分为若干个子系统,可以独立开发、配置或交付它们,也可以在一组分布式计算节点上独立部署它们。还可以在不破坏系统其他部分的情况下独立地进行更改。
3. 定义子系统接口
##### 7.3.3 任务管理策略
在软件设计必须考虑任务管理,以实现应用软件对多用户、多任务的支持,满足并行处理的需求。
##### 7.3.4 分布式实现机制
确定网络拓扑配置、将设计元素分配到网络节点,设计分布处理机制。
##### 7.3.5 数据存储设计
对于实例数据需要持久保存的类,需要设计一种统一存储、读取和修改数据的方法(持久层)。
##### 7.3.6 人机交互设计
设计阶段给出有关人机交互的所有系统成分,包括用户如何操作系统、系统显示信息等。
#### 7.4 系统元素设计
系统元素设计的终点在于如何实现相关的类、关联、属性与操作,定义实现时所需的对象的算法与数据结构。
##### 7.4.1 子系统设计
1. 将子系统行为分配给子系统元素
2. 描述子系统元素(创建一个或多个类图/状态图)
##### 7.4.2 分包设计
1. 将设计元素划分到不同的包
2. 描述包之间的依赖关系
3. 避免包之间的互相依赖,同时保证复用价值高的包不要依赖复用价值低的包
##### 7.4.3 类/对象设计
类、对象设计是设计工作的核心。
主要考虑三个问题:
+ 如何实现分析模型中的边界类、实体类和控制类
+ 解决类设计中的实现问题时如何应用设计模式
+ 系统架构中的全局性觉得如何在类设计中体现
类图的设计过程用文字描述过于复杂,也过于抽象。笔者在此不再赘述。软件工程大作业和实验课都有设计类图的项目,也可以根据课本7.5章的实例了解。
类图的设计一般依赖于时序图,在设计好类的属性和方法后,还需要定义类之间的依赖关系。

设计类还应该加以改进来处理适应编程语言、提高性能、处理错误等非功能性需求。
### 第八章 编码与测试
#### 8.1 编码概述
编码(coding)俗称编程序,编码阶段产生可执行的代码,把软件的需求真正付诸实现。编码阶段也称为实现(implementation)阶段。
##### 8.1.1 编码的目的
编码目的是使用选定的程序设计语言,把设计模型翻译为用该语言书写的源程序。

程序员需要养成良好的编码的风格,而且要十分熟悉使用的语言。
##### 8.1.2 编码的风格
传统程序设计十分强调编码风格(coding style,又称程序设计风格)。程序的目标是在清晰的前提下才追求效率。
+ 先求正确而后求快
+ 先求清楚而后求快
+ 求快不忘保持程序正确
+ 保持程序简单以求快
+ 书写清楚,不要为“效率”牺牲清楚
从控制结构、代码文档化和输入三个方面可以简述编码风格的要求:
+ 使用标准的控制结构
遵循模块逻辑中采用单入口、单出口标准结构这一主要原则,确保翻译出来的程序清晰可读。
+ 实现源代码的文档化
为了提高代码的可维护性,源代码也要实现文档化(code documentation),这主要包括以下三个方面的内容:
+ 有意义的变量名称
+ 适当的注释
+ 标准的书写格式
+ 满足用户友好的输入输出风格
程序的允许要充分考虑人的因素,尽量做到对用户友好(user friendly)
#### 8.2 编码语言与编码工具
分为基础语言、结构化语言、面向对象语言。
计算机专业的学生自大学以来已经大量了解这方面知识,此处略过。
#### 8.4 测试的基本概念
软件测试(software testing)是动态查找程序代码中的各类错误和问题的过程。
##### 8.4.1 目的与任务
测试(testing)的目的与任务:
+ 目的:发现程序的错误
+ 任务:通过在计算机上执行程序,暴露程序中潜在的错误
纠错(debugging)的目的与任务:
+ 目的:定位和纠正错误
+ 任务:消除软件故障,保证程序的可靠运行

##### 8.4.2 测试的特性
1. 挑剔性:抱着为证明程序有错的目的去测试
2. 复杂性:做好一个大型程序的测试,其复杂性不亚于对这个程序的开发
3. 不彻底性:不能证明错误不存在
4. 经济性:要根据重要程度决定测试的投入
##### 8.4.3 测试的种类

##### 8.4.4 测试的文档
一个程序所需的测试用例可以定义为:测试用例={测试数据+期望结果}
而测试结果则为:测试结果={测试数据+期望结果+实际结果}
#### 8.5 黑盒测试和白盒测试
在过去几十年中,软件测试的基本技术没有大的变化。
##### 8.5.1 黑盒测试
黑盒测试就是根据被测试程序功能来进行测试,所以也成为功能测试。有以下几种常用技术。
1. 等价分类法(equivalence partitioning)
把输入数据的可能值分为若干等价类,使每类中的任何一个测试用例,都能代表统一等价类中的其他测试用例。即用少量代表性的例子来代替大量内容相似的测试。
划分等价类不仅要考虑有效等价类,还要考虑无效等价类。若干个无效等价类的测试用例不能合并。

2. 边界值分析法(boundary value analysis)
由于程序员处理边界情况时常常发生疏忽,因此在边界值附近程序出错概率较大。等价分类法的测试数据在各个等价类允许的值域内任意选取,而边界值分析的测试数据必须在边界值附近选取。

3. 错误猜测法
猜测被测程序在哪些地方容易出错,更多地依靠测试人员的直觉与经验。一般用猜错法补充一些例子作为辅助的手段。
此外还有种名为**因果图**法的方法,比较高明,但操作步骤较为复杂,不介绍详情。
##### 8.5.2 白盒测试
以程序的结构为依据,又称为结构测试。
早期白盒测试把注意力放在流程图各个判定框,称为逻辑覆盖测试(logic coverage testing),现在则用程序图替代流程图,称为路径测试(path testing)。
1. 逻辑覆盖测试法
通用流程图来设计测试用例,考察的重点是图中的判定框。

2. 路径测试法
逻辑覆盖测试忽略了程序的执行路径。路径测试离不开**程序图**(program praph)。
程序图实际上是一种简化了的流程图,它是用来考察测试路径的有用工具。程序图保留了控制流的全部轨迹,舍弃了各框的细节。
+ 顺序执行的多个节点可以合并成一个节点
+ 符合条件的判定框,应该先分解成几个简单条件判定框,再画程序图

路径测试就是对程序图种每一条可能的程序执行路径至少测试一次。路径覆盖包含了点覆盖和边覆盖。
而对于安排循环测试,对于单循环结构的路径测试可以包括:
+ 零次循环
+ 一次循环
+ 最大值次循环
多重嵌套循环种,测试路径也应该跟随程序的实际需要来选择。
**选择测试路径的原则**:
+ 尽量选择具有功能含义的路径
+ 尽量用短路径代替长路径
+ 上一条测试路径到下一条从测试路径,尽量减少变动的部分
+ 由简入繁,如果可能先考虑不含循环
+ 不要选取没有明显功能含义的复杂路径
#### 8.6 测试用例设计
与往常一样,如果需要查看具体样例,请查看课本,带上具体样例,基本无可省略。
黑盒测试用例的设计往往会结合等价类、边界值法、猜错法三种方法进行样例设计,而之后则可以用白盒法验证产生的测试用例的充分性。
可以先采用等价分类法,再采用边界值法,但有时反过来效果更好。猜错法一般作为补充使用。
#### 8.7 多模块程序的测试策略
##### 8.7.1 测试的层次性
按照软件工程的观点,多模块程序的测试共包括4个层次。

+ 单元测试:应在编码阶段完成。单元一般以模块或子程序为单位。是测试的基础。单元测试发现错误约占总错误数的65%。
+ 集成测试:将经过单元测试的模块逐步组装成具有良好一致性的完整的程序。
+ 确认测试:
+ 有效性测试(黑盒测试):确认组装完毕的程序是否满足软件需求规格说明书(SRS)的要求。
+ 验收测试:主要由用户进行,可以进行几个星期或者几个月
+ $\alpha$与$\beta$测试:前者在受控环境下,用户在开发者的指导下进行测试。开发者负责记录错误和使用中的问题。后者由最终用户在自己的场所进行,问题由用户记录,不定期汇报给开发者。
+ 系统测试:更大范围的测试,系统可能包括硬件和原有其他软件,是验收工作一部分。
## 下篇 软件工程的近期进展、管理与环境
### 第九章 软件维护
> 软件维护是指软件系统交付使用以后,为了改正或满足新的需要而修改软件的过程。
#### 9.1 软件维护的种类
+ 完善性维护(perfective maintenance)
在使用期间不断改善和加强产品的功能与性能。整个维护工作量中,完善性维护约占50%~60%,居于第一位。
+ 适应性维护(adaptive maintenance)
指软件适应允许环境的改变而进行的一类维护。约占维护工作量25%。
+ 纠错性维护(corrective maintenance)
目的在于纠正在开发期间未能发现的遗留错误。约占维护工作量20%。